Why do PIDs dominate?
Proportional Integral Derivative (PID) controllers represent more than 90% of control loops due to their simplicity, robustness, cost-effectiveness, and versatility, and are the first tool control engineers use to solve feedback control problems [1]. PID controllers require minimal knowledge of system dynamics and can be applied to a wide range of single-input-single-output (SISO) systems. The equation below shows the most often used ‘parallel form’ of a PID:

Applying PID control to a system effectively requires tuning, where the different gains of the PID controller are determined based on the system’s response to a reference demand. The terms Kp, Ki, and Kd are the PID gains and can control how fast, accurate, and ‘damped’ the response is. Tuning these manually or using an algorithm such as the Ziegler-Nichols method results in a controller that is often near optimal for that specific application. But what happens when the system changes over time or more complex external perturbations need to be addressed? This is where PID control, on its own, isn’t enough.
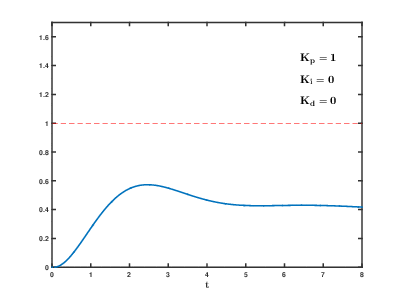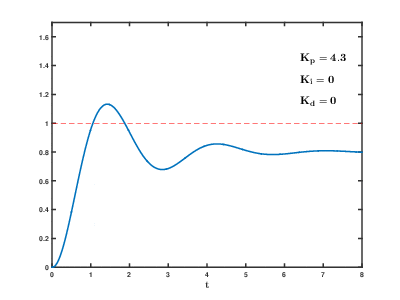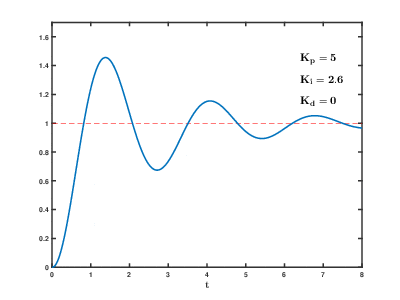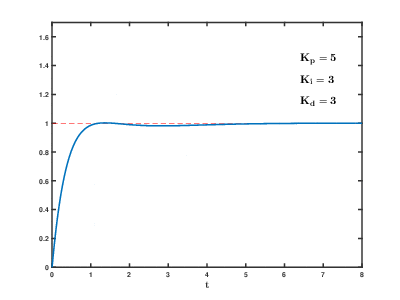
PID control’s drawbacks and traditional alternatives
Some of the most common ways of extending PID control’s capabilities are to utilise multiple instances of PID controllers or maintain multiple different states in a single controller; these techniques are known as cascaded PID control and gain-scheduling, respectively. Gain scheduling changes the gain parameters based on system state to improve performance, but this requires individual tuning of each set of gains. Like simple PID control, if the system changes in an unexpected way, this could leave all the gains inadequate for near-optimal operation. This highlights the problem with PID control in the real world; systems often change or have perturbations that can’t be replicated when tuning PID gains. A control system’s properties can be changed slowly over time by wear or tear, or changed instantly, for example, a conveyor belt used with different masses than commissioned with. Both of these occurrences would most likely require a retuning process to maintain desired operation/near-optimal control.
Model Predictive Control (MPC) is a control technique that uses a model of the real system to sample several possible control actions and select the one most likely to achieve the desired response/result. This allows the controller to take into account changes in the system behaviour in a way that PID controllers cannot. However, MPC can be very computationally expensive and therefore, often requires additional high-spec compute power to run at the control speeds necessary to react quickly to fast-acting perturbations. The greater requirement of compute also means MPC cannot be implemented in-place of PIDs, without the need for large extensions to the available compute power.
The table below summarises some distinctions between PID control, gain-scheduled PID control and MPC:

Each of these techniques has features and flaws, but in most cases in industry, where minimising downtime and retrofits paired with good adaptive/robust performance is key, a new alternative is required.
Why is AI not already used for closed loop control?
The application of Artificial Intelligence (AI), specifically Artificial Neural Networks (ANNs), to control systems is at the forefront of control systems research, but AI has not yet made significant advancements in the field [2]. Some of the aspects that currently limit the application of AI in control systems are:
- The complexity of the phase space [2]
- Gaining sufficient training data to accurately represent and model systems
- The requirement for substantial computational resources to effectively train the AI in a sufficiently large search space
- The unpredictability of disturbances [2]
- AI methods can often find unforeseen disturbances difficult due to lack of generalisation
- Neural networks often require very large structures to embody adaptation/robustness, resulting in very large computational costs and increasing the risk of overfitting to training data
- Implement-ability/Retrofit-ability
- AI methods require very expensive, highly capable compute resources to run at speeds often required by real-time control
Unlocking the potential of AI in control systems requires these and other limitations to be addressed. This calls for a solution that has sufficient training data to represent the real-world system, is adaptable/robust to disturbances, and doesn’t require expensive equipment to run at speeds necessary for real-time control of systems.
A PID alternative using neuroplastic AI
Utilising neuroplasticity and physics-driven training techniques can alleviate the limitations of AI applied to control systems, and when enabled with highly optimised encoding that makes retrofits possible, it represents the first viable AI offering for closed-loop control of real-world systems.
Neuroplasticity is the ability of a neural network to quickly change its predictions in response to new information and has been described as essential for the adaptability and robustness of deep reinforcement learning systems [3]. In practice, utilising neuroplasticity can substantially reduce the topological size of the neural network required for adaptive control, compared to using neural networks with fixed weights. Creating smaller neural networks also reduces the likelihood of ‘overfitting’ to training data, which is where a network fits ‘too well’ to its training data at the detriment of generalisation, and therefore, performance in situations not sufficiently represented in the training data.
AI learning techniques often train using data gathered from a real system, which is guaranteed to be representative of that system in its particular state. However, gathering enough data to represent a system and all its different perturbations is prohibitively time-consuming and sometimes, not possible at all. In most real-world industrial systems, it is not feasible to collect data that maps the whole domain, as inciting failure modes is not permissible, or data cannot be gathered in a ‘rich’ enough state without expensive equipment. This necessitates the use of physics-driven training data, where the data is generated using digital-twin simulations of the real system, similar to MPC. However, unlike MPC, the simulation only runs during the training of the AI controller and isn’t required when deployed. Having a digital-twin simulation also allows for the addition of perturbations and imperfections that the AI can become robust to in the training phase. This technique also allows rare or hypothetical perturbations to be estimated even if real-world data of the perturbation cannot be gathered.
So, when revisiting the limitations of AI for control systems, the techniques mentioned in this section have the following results:
- The complexity of the phase space
- Training data is generated by a physics-driven digital twin
- There are no constraints on how much data you can use for training
- The simulation can sample the generalisation of the AI controller and the adaptability to new systems/situations
- The unpredictability of disturbances
- Perturbations can be represented in the training set
- Neuroplasticity provides adaptability and smaller networks, which are often more generalised
- Implement-ability/Retrofit-ability
- Neuroplasticity generates smaller networks and when these networks are efficiently encoded, they can be retrofit into existing hardware/firmware that contain simpler controller like PIDs
At Luffy AI, we utilise these principles to create AI that can directly replace PIDs in real systems. In practice, this means no requirement for controller tuning, adaptability that maintains near-optimal control even when the system changes, and inexpensive retrofits into existing hardware. We call our PID replacement an ANC (Artificial Neural Controller).
The table below summarises how a Luffy ANC compares to existing methods when applied to real control systems:

A technique that is often used to bridge the reality gap when applying AI to real systems is edge learning [4], which could be argued to adapt in deployment. In traditional edge learning techniques, neural networks adjust their structure in conjunction with the network weights during deployment, aiming to enhance their performance. This methodology can result in networks that can adapt to new or changing conditions gradually, but can lead to problems with assurance due to phenomena such as ‘catastrophic forgetting’, where existing behaviours are ‘forgotten’ in favour of newer strategies that may fit recent data better but may degrade performance in the overall domain.
As an example, in the robotics domain, an AI controller could be trained to grasp delicate items without damaging them, and with the use of edge learning, could use feedback in application to improve its behaviours. But, if the controller was then tasked to pick up heavier items and learned how to do this well using edge learning, returning to the original delicate task would likely lead to the damaging of the delicate items, as the controller’s behaviour has been optimised over time for heavier objects.
An important distinction with Luffy AI’s technology is that the networks adapt in real-time and don’t learn in real-time like edge-learning networks. Luffy AI controllers learn adaptive behaviours in training and don’t change their structure when deployed, meaning that resetting a Luffy AI ANC results in the same controller and behaviour every time. Luffy networks are tasked with finding behaviours and strategies that are applicable in all the training scenarios with small real-time adaptations, no drastic changes in the network itself. Returning to the grasping example, the network would have to find a strategy that doesn’t damage delicate objects and is able to control heavier objects. This network then could be used for delicate and/or heavy grasping without risk of catastrophic forgetting if deployment is subsequently changed.
A case study: AC motor speed control
To control an AC electric motor, a VFD (Variable Frequency Drive) regulates the current and frequency of the electricity delivered to the windings of the motor using a cascaded PID setup, where PIDs work in series to control a system. A downside of this approach is that all these PIDs need to be tuned separately, and their tuning could affect other PIDs in the cascade, leading to complexity and fragility in the process. But this is the industry standard currently built within standard off-the-shelf VFDs from all major manufacturers.
When a VFD and motor are implemented into a plant, the operator often has a choice between a built-in auto-tuning process that requires setup and time, or when system dynamics or accuracy require, manually tuning the system which requires time and highly-skilled engineers. As soon as conditions change due to a change in load or running conditions, then this PID tuning is out of date and may lead to poor performance. If a user knows different loading conditions are going to occur, for example, when controlling the speed of a conveyor belt with different baggage/material masses being transported, then gain-scheduling can be used. In this example, it would then require the operator to set up the plant in each one of the different cases, tune for each case, and then track the state of the system so that the PID can switch gains at the right time (e.g., tracking baggage mass on the belt at all times). This is already a large time cost to the operator, and this is required for each VFD and motor set up as part of the system. An MPC approach could be considered, but then it would require the development of a model representative of the system and the installation of many highly capable computers to run MPCs for each one of the VFDs.
An example of how a Luffy ANC compares to a set of PIDs, that are tuned to each load, is shown in the figure below:

This example clearly highlights the need for a solution that has low operator and installation requirements, adaptability to changing conditions in the system and no need for expensive equipment to enable real-time control.
Using Luffy AI’s ANC approach can deliver real-time adaptive control without the need for expensive equipment, and it can be demonstrated in the case of baggage handling using AC motors, specifically in the replacement of the speed-to-torque control PID. We train an ANC that performs the best in a series of simulations that include parameter variation, perturbations and phenomena such as noise and delays. This ensures performance in the expected domain when applied in hardware. It’s important to note that, unlike PID gain-scheduling, the state of the system does not have to be tracked directly; the ANC will use the existing sensory information (in this example, speed) to infer the state of the system and react accordingly to maintain optimal control. The Luffy AI ANC can then be deployed into a VFD using a firmware upgrade or ran via a PLC, bringing adaptive control without any need for extra sensory data or extra expensive hardware. When in use, the ANC will adapt its control strategy to maintain optimality, without any need for tuning, even when subject to perturbations or changes in the system. This case study shows that an Luffy AI ANC can effectively provide adaptive control without any need for tuning, leading to effort-free commissioning processes and long-term stable and effective closed-loop control.
Luffy AI controllers can also be extended to MIMO (multi-input multi-output) systems, such as drone flight controllers, and can be extended with observable outputs. For example, if in the conveyor belt case study an operator would like to know how much mass is on the belt at a given time, an output can be added to the ANC to predict this. This pairs more traditional applications of AI in predictive maintenance or state estimation into the controller itself, minimising the number of parallel AI instances in a system.
Conclusions
PID control has dominated the industrial control landscape due to its simplicity, robustness, cost-effectiveness, and versatility, and its simple tuning process makes it widely deployable to many SISO systems, and MIMO systems too, with the utilisation of cascaded control and gain scheduling. However, its inadaptability often leads to suboptimal control and therefore, suboptimal industrial processes. MPC is a viable alternative that utilises a simulation model to sample control actions and their results before they’re applied, but require expensive equipment to run in real-time control. The need for low-maintenance and optimal processes call for a computationally efficient but adaptive alternative for real-time control, which Luffy AI controllers provide.
Luffy AI controllers utilise the adaptability and efficiency brought by neuroplasticity applied to artificial neural networks to adapt in real-time to disturbances and changes in the system. Optimised encoding unlocks the opportunity of retrofitting AI control into existing hardware and replacing PID controllers directly without the need for additional sensors or compute power. Luffy AI controllers can control SISO systems at high speeds but are also extensible to MIMO systems, such as drone positional control, and can expose internal network inference, which can give operators information about the system, direct from an existing AI implementation. In application, Luffy AI controllers can utilise adaptability to maintain optimal control, exploit encoding efficiency to directly replace PID controllers in real hardware, and eliminate the need for tuning and computationally expensive processing.
Luffy AI’s technology brings AI from analytics and supervisory tools to a feasible alternative for real-time adaptive control, enabling consistent performance and robustness out of the box.
References
-
- Åström, K.J. and Hägglund, T., 2001. The future of PID control. Control engineering practice, 9(11), pp.1163-1175
- Schöning, J. and Pfisterer, H.J., 2023. Safe and trustful AI for closed-loop control systems. Electronics, 12(16), p.3489.
- Lyle, C., Zheng, Z., Nikishin, E., Pires, B.A., Pascanu, R. and Dabney, W., 2023, July. Understanding plasticity in neural networks. In International Conference on Machine Learning (pp. 23190-23211). PMLR.
- Jonnarth, A., Johansson, O., Zhao, J. and Felsberg, M., 2024. Sim-to-real transfer of deep reinforcement learning agents for online coverage path planning. arXiv preprint arXiv:2406.04920.

